本次夏令营实验室安排的任务是精读并理解IJCAI2018的论文Crowd Counting using Deep Recurrent Spatial-Aware Network,本文记录了我对这篇论文的一些解读
Highlight
人群计数是实际应用中一个非常重要的任务,已有的方法不能很好地处理图片中人群的规模和旋转角度变化的问题,本文提出的 Deep Recurrent Spatial-Aware Network通过使用可学习的空间变化模块结合区域优化过程,首次解决了旋转角度变化的问题,并取得了很好的效果。相比于已有的最优方法,本文提出的方法在WorldExpo’10和UCF CC 50数据集上的效果都取得了很大的进步。
Problem & Challenge
人群计数即估计拥挤场景中的总人数,这在实际生活中十分重要。比如在一些大型活动中,如果能够准确估计出当前场景中的人群密度,就可以安排相应级别的安保措施,从而避免发生踩踏事故。
由于光照和摄像机视角的变化,要准确估计同一个场景的不同图片中的人群密度绝非易事,已有的方法仅处理了人群规模的变化而没有解决摄影角度变化的问题。而且这些方法大多使用了预先设计好的固定网络结构,这使得它们仅能处理有限的规模变化。
Method
本文提出了一种新型网络Deep Recurrent Spatial-Aware Network来完成人群计数的任务,第一次解决了旋转角度变化的问题。
模型整体网络结构如图所示:
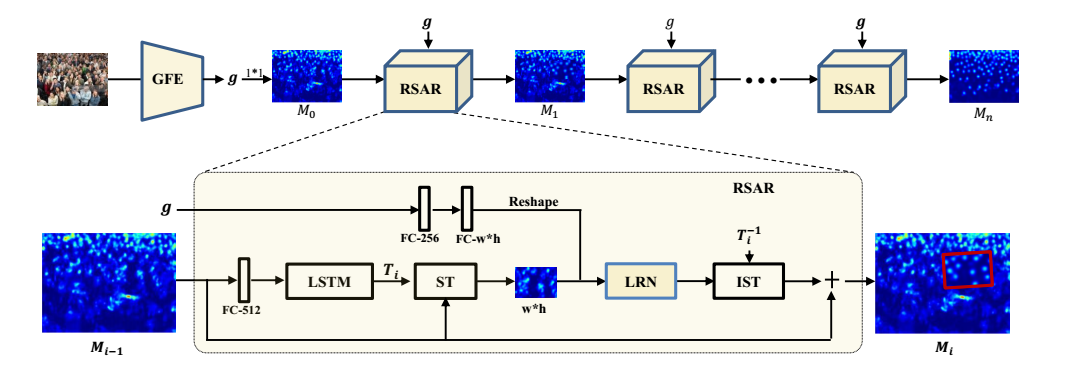
网络总共包含两个模块:Global Feature Embedding(GFE)和Recurrent Spatial-Aware Refinement(RSAR)。
GFE
GFE(Global Feature Embedding)模块对输入的图像进行特征提取,得到的feature map通过$1*1$的卷积运算得到初始的人群密度图$M_0$。
GFE模块网络结构如图所示,包含3列CNN,每一列都有7个不同kernel size、channels的卷积层,并且有3个max-pooling池化层,最终把3列CNN的输出拼接得到全局特征$g$
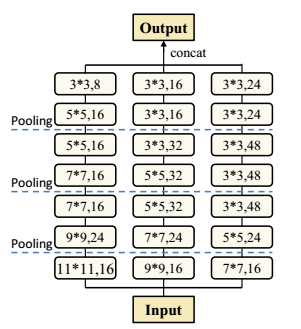
图中的表示卷积核大小为$k * k$,输出channel为$N$
RSAR
RSAR模块用于提高密度图的质量,它通过一个空间转换机制来定位图像中的注意区域,然后利用残差学习来对密度图进行优化。最终在经过$n$次RASR模块的迭代后可以得到一个能够准确估计人群数量的高质量密度图。由此可知RSAR包含两个模块:
- 定位注意区域,核心是LSTM和Spatial transformer Network
- 优化密度图,核心是Local Refinement Network
定义RSAR模块的第$i$次迭代的输入为$M_{i-1 }$。
Attentional Region Localization
首先把$M_{i-1}$通过全连接层编码为512维的特征,用作LSTM的输入:
$c_i$和$h_i$分别代表LSTM的memory cell和hidden state,$h_i$会被通过用全连接层来计算得到变换矩阵$T_i$的参数,根据变换矩阵$T_i$就可以从完整密度图$M_{i-1}$中提取出区域密度图$r_i$:
变换矩阵$T_i$允许对输入密度图进行平移、旋转、缩放操作:
$ST$代表Spatial transformer Network,能够对feature map进行空间变换,输出一张新的图像,$ST$的空间不变性保证了在对图像进行平移、旋转、缩放等操作后模型仍能正确识别这张图片。$ST$是一个独立的模块,可以在CNN的任何地方插入。
由于训练过程中变换矩阵$T_i$的存在,训练好的网络能够处理人群规模和旋转角度变化的问题。作者也对变换矩阵所允许的操作进行了简化测试,发现在允许平移、旋转和缩放操作时训练出的网络具有最好的效果。
通过双线性插值法可以把区域密度图$r_i$ resize成给定的大小$w * h$
Region Density Map Refinement
已有的工作证明了对全局上下文信息建模在人群计数任务中的重要性,因此作者在这个模块中也考虑了这一点。
首先把全局特征$g$用两个堆叠的全连接层进行编码,输出512维的向量,然后把输出reshape成$w*h$的tensor可以得到global context map $c_g$,得到了$r_i$和$c_g$后就可以用LRN模块来进行密度图的优化。
LRN模块网络结构跟GFE模块很相似:
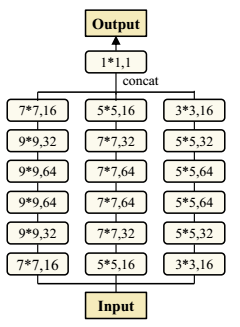
LRN(Local Refinement Network)模块把拼接之后的$r_i$和$c_g$作为输入,输出这块区域的残差图。最后通过把$M_{i-1}$和inverse之后的残差图相加就可以得到优化过后的密度图$M_i$:
IST(inverse spatial transformer)能够根据$T^{-1}_i$来把残差图转换回注意区域,$T^{-1}_i$是变换矩阵$T_i$的逆
Optimization & Evaluation
对于图片的预处理视不同的数据集而定,但都需要把所有图片处理成统一的大小。
图片$I_i$的ground truth的密度图$D_i$的生成参考了Learning to count objects in images 这篇论文,按照数据集给定的人头标注的点把图片转换成密度图。要从密度图计算出人数则是对所有标注出的点在密度图上求和得到:
在训练过程中损失函数定义如下:
CNN的filter和全连接层的参数通过deviation为0.01的截断正态分布来初始化;初始学习率为$10^{-4}$,并且每1000轮迭代乘以0.98,用以实现学习率衰减;batch size设置为1;使用Adam优化器;RSAR优化迭代次数为30。
模型的评估方式有两种,平均绝对误差(MAE)和均方误差(MSE):
$N$是测试图片总数,$p_i$和$\hat{p_i}$分别是第$i$个图片的ground truth count和估计值。
Result
作者在ShanghaiTech、UCF CC 50、MALL 、WorldExpo’10这4个数据集上都进行了实验(这4个数据集均给出了人头标注的点的坐标),并与已有最佳方法进行了比较,本文这种方法都取得了最优的结果。
下面这张图以可视化的形式展现了模型的效果:

用初始的密度图$M_0 $估计出的人群数量误差很大,而在经过了迭代优化之后的密度图就可以用来准确地估计人群数量了。
Conclusion
人群计数是计算机视觉中比较重要的一个问题,具有很高的应用价值。本文提出的Deep Recurrent Spatial-Aware Network利用空间变换机制和残差学习对人群密度图的局部区域不断进行迭代优化,最终得到可用于准确人群计数的高质量密度图。我认为本文最大的创新点在于:
- 根据LSTM学习长期依赖信息的特点,用LSTM来捕捉密度图的历史信息和行为转换
- 引入了变换矩阵$T_i$,从而使得训练好的模型能够很好地处理人群规模和旋转角度变化的问题
- 提出了一个可用作通用框架的密度图优化模块
作者计划在未来的研究中把这个模型纳入其他已有的框架中,这有点类似于ELMo这种模型的应用,用以提升下游任务的效果。